Decoding Hallucinations in LLM: Causes and Solutions — PART 2
Decoding Hallucinations in LLM: Causes and Solutions — PART 2

Hallucinations in Large Language Models (LLMs) like GPT-4 can undermine the reliability of these powerful tools. In Part 1, we explored the causes of hallucinations in LLMs. In this section, we’ll dive into detailed solutions to address these issues, ensuring more accurate and reliable outputs.
Context Misunderstanding
Solution: Enhancing Contextual Understanding
- Contextual Embeddings:
Use advanced contextual embedding techniques to help the model better understand the nuances and context of the input.
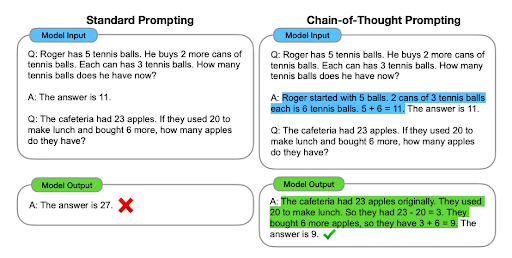
Example: Implement transformers that focus on contextual relationships within the input data. - Prompt Engineering:
Provide clear and detailed prompts to guide the model.
Example: Instead of asking, “Tell me about the Great Wall,” use, “Provide historical details about the construction and purpose of the Great Wall of China.” - Context Windows:
Increase the context window size to allow the model to consider more surrounding information.
Example: Use models that support larger context windows, like GPT-4, which can handle more extensive input sequences.
Ambiguity in Prompts
Solution: Reducing Ambiguity
- Specificity in Prompts:
Formulate prompts with clear, specific questions or instructions.
Example: Instead of “What happened in 1969?” use, “List significant global events that occurred in 1969.” - Prompt Templates:
Develop prompt templates that provide a structured format for queries.
Example: Use templates like “Explain [event] that happened in [year]” to reduce ambiguity. - Clarification Mechanisms:
Implement mechanisms for the model to ask for clarification when the prompt is ambiguous.
Example: If the model detects ambiguity, it could respond with, “Could you please clarify which event in 1969 you are referring to?”
Overgeneralization
Solution: Enhancing Precision
- Domain-Specific Training:
Fine-tune the model on specific domains to improve accuracy in those areas.
Example: Train a separate model for historical events to reduce overgeneralization. - Detailed Prompts:
Encourage users to provide detailed prompts to guide the model’s response.
Example: Instead of “Explain the causes of World War II,” use, “Explain the political, economic, and social causes of World War II.” - Model Regularization:
Apply regularization techniques to prevent the model from making overly broad generalizations.
Example: Use dropout or other regularization methods during training to improve model robustness.
Inference Errors
Solution: Enhancing Logical Consistency
- Logical Validation:
Implement logic-based validation checks to verify the correctness of the model’s inferences.
Example: Use external logic engines to cross-check factual statements made by the model. - Fact-Checking Modules:
Integrate fact-checking modules that cross-reference outputs with reliable databases.
Example: Use APIs from fact-checking services to validate claims about historical figures or events. - Human-in-the-Loop:
Employ human reviewers to validate and correct the model’s outputs, particularly for critical applications.
Example: In educational or medical applications, have experts review the content before it is delivered to users.
from factcheck_api import FactChecker
fact_checker = FactChecker(api_key="your_api_key")
def validate_facts(text):
return fact_checker.check(text)
prompt = "Describe the life of Albert Einstein."
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
output = model.generate(input_ids)
response = tokenizer.decode(output, skip_special_tokens=True)
if validate_facts(response):
print(response)
else:
print("Fact-checking failed. Please verify the information.")
*Caption: Integrating fact-checking modules ensures logical consistency and accuracy.*
Tokenization Issues
Solution: Improving Tokenization
- Advanced Tokenizers:
Use tokenizers that handle complex languages and multi-word expressions more effectively.
Example: Implement Byte Pair Encoding (BPE) or SentencePiece tokenizers to improve accuracy. - Tokenization Rules:
Define specific tokenization rules for different languages and contexts.
Example: Customize tokenization for specific use cases, such as legal or medical texts. - Pre-Processing:
Apply pre-processing steps to standardize input data before tokenization.
Example: Normalize text to handle variations in spelling, punctuation, and formatting.
Training Cutoff
Solution: Regular Updates and Clarifications
- Regular Model Updates:
Regularly update the model with new data to incorporate the latest information.
Example: Schedule periodic retraining sessions to keep the model up-to-date. - Explicit Cutoff Information:
Clearly communicate the model’s training cutoff date in the documentation and responses.
Example: Automatically include a disclaimer in the model’s outputs about the training cutoff date. - External Data Sources:
Integrate external data sources to fetch the latest information.
Example: Use APIs to pull real-time data for questions about current events or recent developments.
Model Architecture Limitations
Solution: Enhancing Model Design
- Hybrid Models:
Combine LLMs with other AI models to leverage the strengths of each.
Example: Use a hybrid approach where LLMs handle natural language processing and other models manage specific tasks like reasoning or memory. - Modular Architecture:
Design modular architectures where different components handle different aspects of language understanding.
Example: Separate modules for syntax, semantics, and pragmatics to improve overall performance. - Continuous Research:
Invest in ongoing research to explore new architectures and training methods.
Example: Experiment with novel neural network architectures and training algorithms to enhance model capabilities. - Enhancing Model Architecture
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "gpt-4"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Fine-tuning on a specific domain
model.train()
Conclusion
Hallucinations in Large Language Models pose a significant challenge, but with the right strategies, their impact can be minimized. By enhancing contextual understanding, reducing ambiguity, refining prompts, integrating fact-checking modules, improving tokenization, regularly updating models, and advancing model architecture, we can significantly improve the accuracy and reliability of LLM outputs.
As AI continues to evolve, ongoing efforts to address and mitigate hallucinations will be crucial. Through a combination of technological advancements and practical implementations, we can ensure that LLMs remain valuable tools for various applications, driving innovation and benefiting society at large.
Part1: https://medium.com/@anuj0456/decoding-hallucinations-in-llm-causes-and-solutions-part-1-b4c67c00c1e6