-
AiLert: From Late-Night Debugging to Community-Driven AI News Platform

It all started this winter during a particularly frustrating 3 AM debugging session. While hunting down a bug in my ML model, I had about…
-
How 11 Years of Kaggle Competitions Became My Ultimate Data Science Learning Tool
When I started my data science journey six years back I used to look for ways to improve my skills. One day I cam accross Kaggle. For…
-
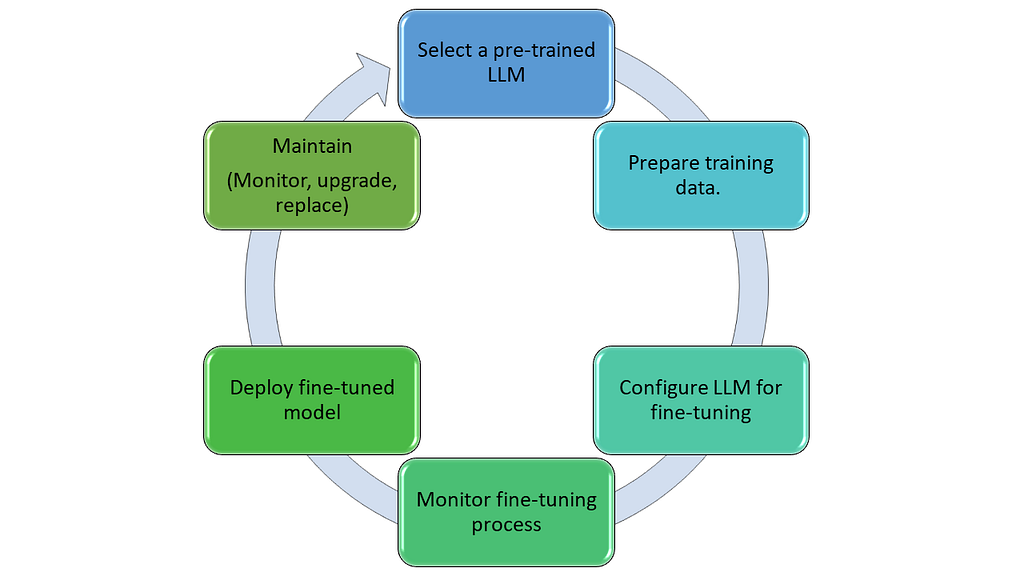
A-2-Z of LLM Model Fine-Tuning

Fine-tuning large language models (LLMs) is an essential step for anyone looking to leverage AI for specialized tasks. While these models…
-
Decoding Hallucinations in LLM: Causes and Solutions — PART 2
Decoding Hallucinations in LLM: Causes and Solutions — PART 2

Hallucinations in Large Language Models (LLMs) like GPT-4 can undermine the reliability of these powerful tools. In Part 1, we explored the causes of hallucinations in LLMs. In this section, we’ll dive into detailed solutions to address these issues, ensuring more accurate and reliable outputs.
Context Misunderstanding
Solution: Enhancing Contextual Understanding
- Contextual Embeddings:
Use advanced contextual embedding techniques to help the model better understand the nuances and context of the input.
Example: Implement transformers that focus on contextual relationships within the input data. - Prompt Engineering:
Provide clear and detailed prompts to guide the model.
Example: Instead of asking, “Tell me about the Great Wall,” use, “Provide historical details about the construction and purpose of the Great Wall of China.” - Context Windows:
Increase the context window size to allow the model to consider more surrounding information.
Example: Use models that support larger context windows, like GPT-4, which can handle more extensive input sequences.
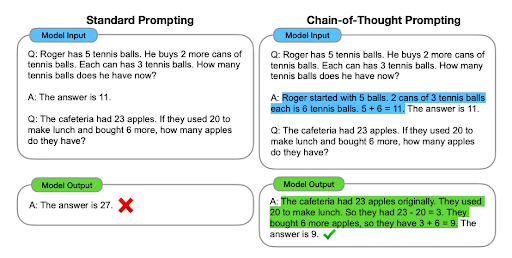
Ambiguity in Prompts
Solution: Reducing Ambiguity
- Specificity in Prompts:
Formulate prompts with clear, specific questions or instructions.
Example: Instead of “What happened in 1969?” use, “List significant global events that occurred in 1969.” - Prompt Templates:
Develop prompt templates that provide a structured format for queries.
Example: Use templates like “Explain [event] that happened in [year]” to reduce ambiguity. - Clarification Mechanisms:
Implement mechanisms for the model to ask for clarification when the prompt is ambiguous.
Example: If the model detects ambiguity, it could respond with, “Could you please clarify which event in 1969 you are referring to?”
Overgeneralization
Solution: Enhancing Precision
- Domain-Specific Training:
Fine-tune the model on specific domains to improve accuracy in those areas.
Example: Train a separate model for historical events to reduce overgeneralization. - Detailed Prompts:
Encourage users to provide detailed prompts to guide the model’s response.
Example: Instead of “Explain the causes of World War II,” use, “Explain the political, economic, and social causes of World War II.” - Model Regularization:
Apply regularization techniques to prevent the model from making overly broad generalizations.
Example: Use dropout or other regularization methods during training to improve model robustness.
Inference Errors
Solution: Enhancing Logical Consistency
- Logical Validation:
Implement logic-based validation checks to verify the correctness of the model’s inferences.
Example: Use external logic engines to cross-check factual statements made by the model. - Fact-Checking Modules:
Integrate fact-checking modules that cross-reference outputs with reliable databases.
Example: Use APIs from fact-checking services to validate claims about historical figures or events. - Human-in-the-Loop:
Employ human reviewers to validate and correct the model’s outputs, particularly for critical applications.
Example: In educational or medical applications, have experts review the content before it is delivered to users.
from factcheck_api import FactChecker
fact_checker = FactChecker(api_key="your_api_key")
def validate_facts(text):
return fact_checker.check(text)
prompt = "Describe the life of Albert Einstein."
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
output = model.generate(input_ids)
response = tokenizer.decode(output, skip_special_tokens=True)
if validate_facts(response):
print(response)
else:
print("Fact-checking failed. Please verify the information.")
*Caption: Integrating fact-checking modules ensures logical consistency and accuracy.*Tokenization Issues
Solution: Improving Tokenization
- Advanced Tokenizers:
Use tokenizers that handle complex languages and multi-word expressions more effectively.
Example: Implement Byte Pair Encoding (BPE) or SentencePiece tokenizers to improve accuracy. - Tokenization Rules:
Define specific tokenization rules for different languages and contexts.
Example: Customize tokenization for specific use cases, such as legal or medical texts. - Pre-Processing:
Apply pre-processing steps to standardize input data before tokenization.
Example: Normalize text to handle variations in spelling, punctuation, and formatting.
Training Cutoff
Solution: Regular Updates and Clarifications
- Regular Model Updates:
Regularly update the model with new data to incorporate the latest information.
Example: Schedule periodic retraining sessions to keep the model up-to-date. - Explicit Cutoff Information:
Clearly communicate the model’s training cutoff date in the documentation and responses.
Example: Automatically include a disclaimer in the model’s outputs about the training cutoff date. - External Data Sources:
Integrate external data sources to fetch the latest information.
Example: Use APIs to pull real-time data for questions about current events or recent developments.
Model Architecture Limitations
Solution: Enhancing Model Design
- Hybrid Models:
Combine LLMs with other AI models to leverage the strengths of each.
Example: Use a hybrid approach where LLMs handle natural language processing and other models manage specific tasks like reasoning or memory. - Modular Architecture:
Design modular architectures where different components handle different aspects of language understanding.
Example: Separate modules for syntax, semantics, and pragmatics to improve overall performance. - Continuous Research:
Invest in ongoing research to explore new architectures and training methods.
Example: Experiment with novel neural network architectures and training algorithms to enhance model capabilities. - Enhancing Model Architecture
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "gpt-4"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Fine-tuning on a specific domain
model.train()Conclusion
Hallucinations in Large Language Models pose a significant challenge, but with the right strategies, their impact can be minimized. By enhancing contextual understanding, reducing ambiguity, refining prompts, integrating fact-checking modules, improving tokenization, regularly updating models, and advancing model architecture, we can significantly improve the accuracy and reliability of LLM outputs.
As AI continues to evolve, ongoing efforts to address and mitigate hallucinations will be crucial. Through a combination of technological advancements and practical implementations, we can ensure that LLMs remain valuable tools for various applications, driving innovation and benefiting society at large.
Part1: https://medium.com/@anuj0456/decoding-hallucinations-in-llm-causes-and-solutions-part-1-b4c67c00c1e6
- Contextual Embeddings:
-
Decoding Hallucinations in LLM: Causes and Solutions — PART 1
Decoding Hallucinations in LLM: Causes and Solutions — PART 1

Large Language Models (LLMs) like GPT-4 have become the cornerstone of numerous applications, ranging from chatbots to advanced content generation tools. Despite their impressive capabilities, these models can occasionally produce outputs that are incorrect or nonsensical — a phenomenon known as “hallucination.” Understanding why hallucinations occur in LLMs and how to mitigate them is crucial for developers and businesses relying on these models.
What is Hallucination in LLMs?
Hallucination in the context of LLMs refers to the generation of outputs that are factually incorrect, irrelevant, or nonsensical. These errors can range from minor inaccuracies to significant deviations from reality. While LLMs are designed to predict the next word in a sequence based on the input they receive, they sometimes generate information that is not grounded in the provided context or real-world knowledge.
Causes of Hallucination in LLMs
- Context Misunderstanding
LLMs rely heavily on context to generate relevant responses. However, they can misunderstand or misinterpret the context or nuances of a prompt, leading to incorrect or irrelevant outputs.
Example:
Prompt: “Tell me about the Great Wall.”
Response: “The Great Wall of China was built in the 5th century BC to prevent Mongolian invasions.”
Correction: The Great Wall’s construction started as early as the 7th century BC, but significant construction occurred during the Ming Dynasty (1368–1644). - Ambiguity in Prompts
Vague or ambiguous prompts can cause the model to guess the intended meaning, often leading to hallucinated information.
Example:
Prompt: “What happened in 1969?”
Response: “The Berlin Wall fell in 1969.”
Correction: The Berlin Wall fell in 1989. A clearer prompt, such as “What significant events occurred in 1969?”, could yield better results. - Overgeneralization
LLMs may overgeneralize from the patterns they learned during training, producing inaccurate or overly broad responses.
Example:
Prompt: “Explain the causes of World War II.”
Response: “World War II was caused by the assassination of Archduke Franz Ferdinand.”
Correction: The assassination of Archduke Franz Ferdinand led to World War I, not World War II. A more detailed prompt can help refine the response. - Inference Errors
The model might make logical leaps or infer relationships that don’t exist, resulting in fabricated or incorrect information.
Example:
Prompt: “Describe the life of Albert Einstein.”
Response: “Albert Einstein was awarded the Nobel Prize in Physics for his theory of relativity.”
Correction: Einstein was awarded the Nobel Prize for his explanation of the photoelectric effect, not for his theory of relativity. - Tokenization Issues
Problems in how text is broken down into tokens can lead to misunderstandings and incorrect outputs.
Example:
Prompt: “Translate ‘sauerkraut’ to French.”
Response: “Sauerkraut in French is ‘choucroute garnie’.”
Correction: “Choucroute garnie” is a specific Alsatian dish. The correct translation for “sauerkraut” is simply “choucroute.” - Training Cutoff
The model’s training only includes data up to a certain point (e.g., GPT-4’s training cutoff in September 2021), missing out on more recent developments and information.
Example:
Prompt: “Who is the current president of the United States?”
Response: “As of my last training data in September 2021, the president is Joe Biden.”
Correction: Always clarify the model’s training cutoff date in prompts or look up recent information manually. - Model Architecture Limitations
The inherent design and limitations of the model architecture can contribute to the generation of hallucinated content. Despite advances, LLMs may still lack the ability to fully understand complex human languages and contexts.
In Part 2, we will explore a range of techniques to mitigate hallucinations in large language models, ensuring their outputs are more accurate and reliable. This includes clarifying context, reducing ambiguity, refining prompts, using external verification, updating training data, improving tokenization, and regular monitoring and fine-tuning.
Part2: https://medium.com/@anuj0456/decoding-hallucinations-in-llm-causes-and-solutions-part-2-cae2c0c146fb
- Context Misunderstanding
-
The REAL Advance RAG with Images and Tables
In the realm of natural language processing (NLP), the integration of images and tables into text has been a longstanding challenge…
-
The Incomplete context in RAG
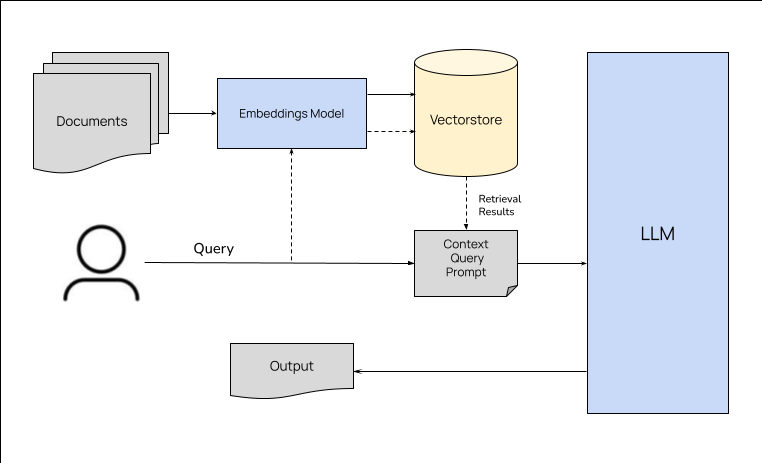
Introduction: In the realm of AI and natural language processing (NLP), context is king. It shapes the way models generate responses…
-
Realistic and consistent responses from LLMs by leveraging three senses

This blog is inspired from arXiv:2312.16233
Language models like GPT4, BARD, BedRock have been making quite a splash lately! From improving natural language understanding to aiding in various applications like chatbots, translation, and content generation, large language models (LLMs) have been at the forefront of AI advancements. The research and development in this field have led to more nuanced and context-aware language models, enabling better communication between humans and machines. The realism and consistency of these responses can be further enhanced by providing richer information of the agent being mimicked.
But due to the significant computational resources required for training such models, prompt tuning has emerged as a crucial aspect of optimizing LLM performance. Recent research has explored various techniques to generate more realistic responses through effective prompt engineering, such as prompting a relevant pseudo dialogue or providing detailed information of the scene, relations, and attributes.The innate context limit of LLMs poses a challenge for maintaining a consistent conversational memory.
To address these challenges, a multi-pronged approach aimed at enhancing the efficacy of prompts for LLMs can be used:
- Information-rich Prompting — Initialize and continuously update the prompts so that it provides multi-aspect information on the character.
- Within-prompt Self Memory Management — To mitigate the limitation of context length, make the language model to summarize the history log and maintain it in the prompt.
- Benchmark Dataset — To overcome the scarcity of useful datasets for evaluation, augment Cornell MovieDialog Corpus2 via GPT-3.5 Turbo, a model known for its strong capabilities comparable to those of fine-tuned LLMs
Results
Each component in the approach helps generate a better utterance.
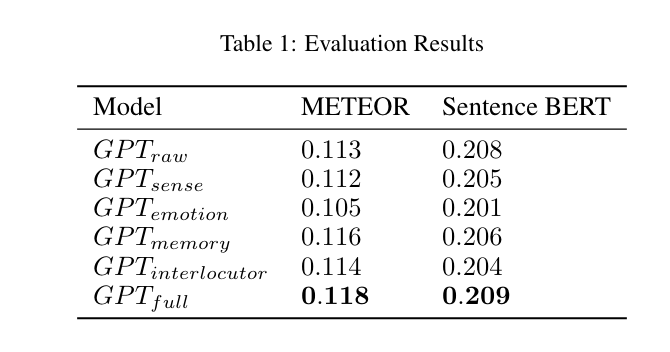
In conclusion, the study highlights the effectiveness of information-rich prompting in enhancing the naturalness and realism of utterance generation when the language model emulates a fictional character.
REFERENCE: arXiv:2312.16233
-
Can ChatGPT really be considered creative?
Language plays an important role in our lives and that is why NLP(Natural Language Processing) has been a very important branch of AI. NLP involves using computational methods to analyze and understand human language. This includes tasks such as text classification, sentiment analysis, machine translation, speech recognition, and chatbot development. AI has made significant achievements in NLP, improving our ability to understand, analyze, and generate natural language. Since the invention of transformers, we have witnessed a very fast acceleration of the pace of development in the past decade. And now with the evolution of transformers from BERT to GPT the possibility of exploiting large-scale data sets has led to the definition of the so-called foundation models, which are able to achieve state-of-the-art performance in a variety of tasks.
LLMs have captivated the imagination of millions of people, also thanks to a series of entertaining demonstrations and open tools released to the public. The examples are many from poetry or storytelling to culinary recipes and the results are often remarkable.
Notwithstanding, it is not obvious whether these “machines” are truly creative, at least in the sense originally discussed by Ada Lovelace (Menabrea and Lovelace, 1843). LLMs have already been analyzed (and sometimes criticized) from different perspectives, e.g., fairness (Bender et al., 2021), concept understanding (Bender and Koller, 2020), societal impact (Tamkin et al., 2021), and anthropomorphism (Shanahan, 2022) just to name a few. However, a critical question has not been considered yet: can LLMs be considered creative?’’
Margaret Boden defines creativity as “the ability to come up with ideas or artifacts that are new, surprising and valuable” (Boden, 2003). In other words, Boden implicitly derives criteria that can be used to identify a creative product. They suggest that creativity is about novelty, surprise and value. We will refer to them as Boden’s three criteria. We will analyze to what extent state-of-the-art LLMs satisfy them and we will question if LLMs can be really considered creative.
Value refers to utility, performance, and attractiveness (Maher, 2010). It is also related to both the quality of the output, and its acceptance by the society. Due to the large impact LLMs are already having (Bommasani et al., 2021) and the quality of outputs of the systems based on them (Stevenson et al., 2022), it is possible to argue that the artifacts produced by them are indeed valuable.
Novelty refers to the dissimilarity between the produced artifact and other examples in its class (Ritchie, 2007). However, it can also be seen as the property of not being in existence before. This is considered in reference to either the person who comes up with it or the entire human history. The former is referred to as psychological creativity (shortened as P-creativity), whereas the latter as historical creativity (shortened as H-creativity) (Boden, 2003). While the difference appears negligible, it is substantial when discussing LLMs in general. Considering these definitions, a model writing a text that is not in its training set would be considered as P-novel, but possibly also H-novel, since LLMs are commonly trained on all available data. Their stochastic nature and the variety of prompts that are usually provided commonly lead to novel outcomes (McCoy et al., 2021); LLMs may therefore be capable of generating artifacts that are also new. However, one should remember how such models learn and generate. Even if prompted with the sentence “I wrote a new poem this morning:”, they would complete it with what is most likely to follow such words, e.g., something close to what others have written in the past (Shanahan, 2022). It is a probabilistic process after all. The degree of dissimilarity would therefore be small by design. High values of novelty would be caused either by accidental, out-of-distribution productions, or by a careful prompting, i.e., one that would place the LLM in a completely unusual or unexpected (i.e., novel) situation.
Surprise instead refers to how much a stimulus disagrees with expectation (Berlyne, 1971). It is possible to identify three kinds of surprise, which correspond to three different forms of creativity. Combinatorial creativity involves making unfamiliar combinations of familiar ideas. Exploratory creativity requires finding new, unexplored solutions inside the current style of thinking. Transformational creativity is related to changing the current style of thinking (Boden, 2003). These three different forms of creativity involve surprise at increasing levels of abstraction: combining existing elements, exploring for new elements coherent with the current state of the field, and transforming the state of the field so as to introduce other elements. The autoregressive nature of classic LLMs make them unlikely to generate surprising products (Bunescu and Uduehi, 2019), since they are essentially trained to follow the current data distribution (Shanahan, 2022). By relying only on given distributions and being trained on them, LLMs might at most express combinatorial creativity. Of course, specific different solutions may be generated by means of prompting or conditioning. For instance, recent LLMs are able to write poems about mathematical theories, a skill that requires the application of a certain existing style to a given topic, yet leading to new and unexplored solutions. However, the result would hardly be unexpected for whom has prompted the text. For an external reader, the surprise would probably come by the idea of mathematical theories in verses, which is due to the user (or by the initial astonishment of a machine capable of it (Waite, 2019)). Transformational creativity is not achievable by means of the current LLM training solutions.
In conclusion, while LLMs are capable of producing artifacts that are valuable, achieving novelty and surprise appears to be more challenging as their inner autoregressive nature seems to prevent them from reaching transformational creativity.
-
Functional Testing using ChatGPT
By now everybody in the tech industry must have heard about ChatGPT and its power. By using simple prompts anybody can write code in a matter of seconds and in fact build an application. However, people ask me what else ChatGPT can do. Though I tell them there is no limit to the capabilities of where and how ChatGPT can be used, one important area where I see ChatGPT being used in coming years is functional testing. Let's first define functional testing.
What is Functional Testing?
As described on Wikipedia

In simple words testing functionalities by feeding input and examining the output is called functional testing.
There are many types of functional testing:
- Unit Testing
- Smoke Testing
- Sanity Testing
- Regression Testing
- Integration Testing
- Beta/ Usability Testing
We will not go into details for each one of them as this post is not about functional testing in particular. But what is important here is to understand how we define a use case for these tests. While writing a use case a tester has to describe the following 4 things:
- Description
- Preconditions
- Steps
- Expected result
So far testers have been following the above template in order to test the functionalities of an application.
Sounds pretty boring and tough?
However, with ChatGPT this is no more arduous work. In fact, defining test cases has become the easiest task for testers as all they have to do is use the right set of prompts to generate a test case. Recently I asked ChatGPT to:
Me: List some functional tests case for an e-commerce app that has OTP-based login along with forgot password functionality. The application also has a signup feature that accepts name, dob and email address to create an account.
ChatGPT Response:
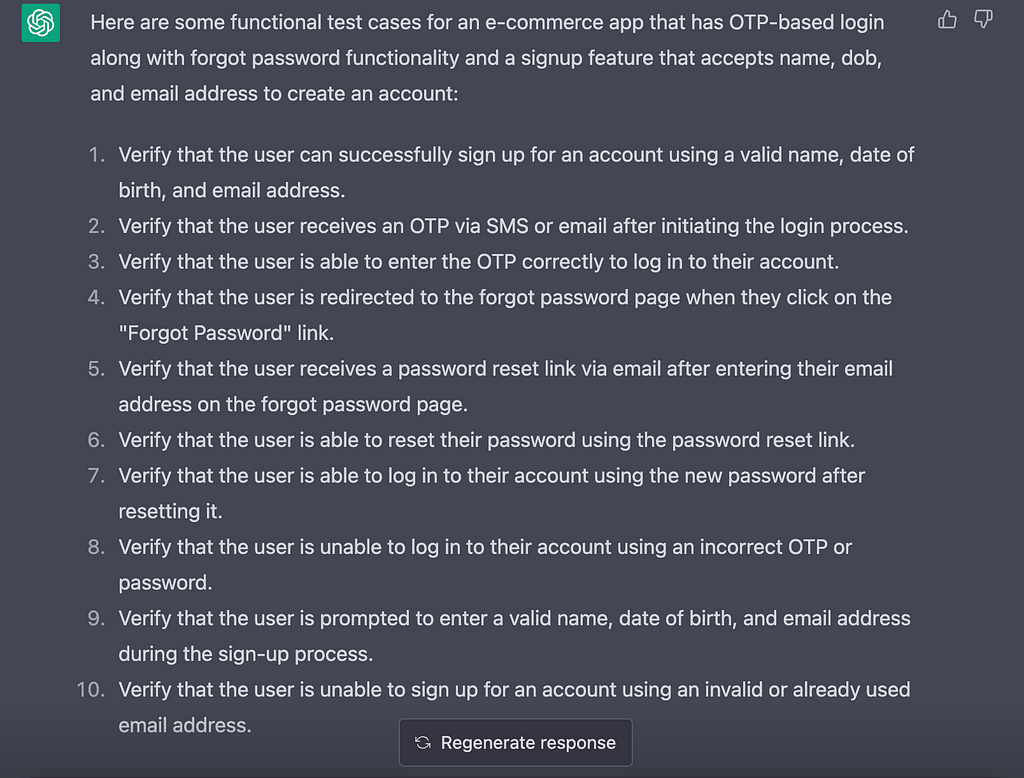
As you can see it has clearly covered all the scenarios to check the login functionality of an app. Looking at the response I went 1 step ahead and asked ChatGPT
Me: Also define security test cases for the above-mentioned functionality. Also define the error message if user already exists in the database.

Again ChatGPT was able to cover all the scenarios. This shows how easy it can become for testers to define test cases that earlier used to take them days to write.
What is worrisome over here is that over the coming years, testers may start losing their jobs as with time ChatGPT will improve and so it's time for testers to upskill themselves before it's too late to start new!